https://school.programmers.co.kr/learn/courses/30/lessons/17677
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
Level 2
간단한 구현이지만 활용할 자료구조가 없어 구현하는데 약간 시간을 들인 문제. 두 문자열의 자카드 유사도를 구해야한다.

이런 방식으로 문자열을 나눠 판별하며 다음과 같은 조건을 만족해야한다.
1. 알파벳 영어 대, 소문자가 아니라면 유사도 원소로 치지 않는다.
(위와 같이 공백이라는 예외 대상이 나오면 건너 뛰어야한다)
2. 대문자와 소문자를 서로 구분해야한다.
(대문자를 소문자로 바꾸던 반대의 경우던 구현해야 한다)
따라서 이러한 조건 때문에 미리 문자열을 바꿔놓고 구하면 제대로된 자카드 원소들을 구할 수 없다.
또한 중복 대상을 제거하지 않으면서 진행해야하기 때문에 집합 클래스도 사용할 수 없다.
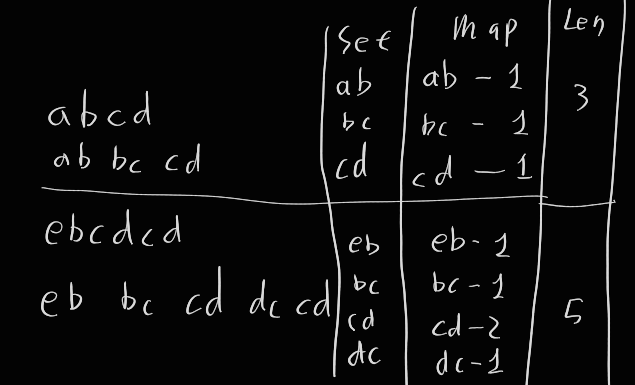
그래서 나는 위와 같이 3개의 구분자를 만들어 솔루션을 구현했다.
0. 문제에서 제시하는 조건을 만족하며 진행한다.
1. 중복은 제거된 자카드 원소들의 문자열 리스트를 만든다.
2. 자카드 원소를 키, 갯수를 값으로 가지는 맵을 만든다.
3. 자카드 원소의 총 갯수를 구한다.
4. 교집합을 구할때 1번 리스트 두 개를 비교해 교집합 원소들을 구한다.
5. 갯수는 해시에서 가져와 더 작은 것으로 친다.
6. 4번, 5번의 총합을 교집합의 갯수로 구한다.
7. 주어진 문자열 1, 2의 자카드 원소 총합 - 교집합 갯수로 합집합 갯수를 구한다.
8. 자카드 유사도를 구한다. (단, 공집합의 경우 분모가 0 이 되므로 1을 반환한다)
import java.util.*;
public class Solution {
public int solution(String str1, String str2) { //뉴스 클러스터링
ArrayList<String> strSet1 = new ArrayList<String>(); //1번 문자열 중복 제거된 원소 집합
ArrayList<String> strSet2 = new ArrayList<String>(); //2번 문자열 중복 제거된 원소 집합
HashMap<String, Integer> strMap1 = new HashMap<String, Integer>(); //1번 문자열 원소 갯수 해시 맵
HashMap<String, Integer> strMap2 = new HashMap<String, Integer>(); //2번 문자열 원소 갯수 해시 맵
int strSet1Size = makeSet(str1, strMap1, strSet1); //1번 문자열 중복 포함 총 길이
int strSet2Size = makeSet(str2, strMap2, strSet2); //2번 문자열 중복 포함 총 길이
double commonSetCnt = getCommonSetCnt(strMap1, strSet1, strMap2, strSet2); //교집합 원소 갯수
double unionSumCnt = strSet1Size + strSet2Size - commonSetCnt; //합집합 원소 갯수
return unionSumCnt == 0 ? 65536 : (int) Math.floor((commonSetCnt/unionSumCnt)*65536); //분모가 0일 경우 자카드 == 1, 아니면 정상 연산 후 반환
}
public int getCommonSetCnt(HashMap<String, Integer> strMap1, ArrayList<String> strSet1, HashMap<String, Integer> strMap2, ArrayList<String> strSet2){
int answer = 0;
ArrayList<String> simStrSet = strSet1.size() > strSet2.size() ? strSet2 : strSet1; //두 문자열 중 덜 복잡한 문자열 집합
HashMap<String, Integer> simStrMap = strSet1.size() > strSet2.size() ? strMap2 : strMap1; //두 문자열 중 덜 복잡한 문자열 해시
HashMap<String, Integer> varStrMap = strSet1.size() > strSet2.size() ? strMap1 : strMap2; //두 문자열 중 복잡한 문자열 해시
for (String tempSet : simStrSet) {
if (!varStrMap.containsKey(tempSet)) //더 많은 종류를 가진 집합 - 덜 많은 종류를 가진 집합
continue;
answer += Math.min(simStrMap.get(tempSet), varStrMap.get(tempSet)); //교집합의 원소일 경우 더 작은 갯수를 교집합 원소 갯수로 가져감
}
return answer;
}
public int makeSet(String str, HashMap<String, Integer> strMap, ArrayList<String> strSet){
int answer = 0;
for(int idx = 0; idx < str.length()-1; idx++){
if(isCustomAlpha(str.charAt(idx)) || isCustomAlpha(str.charAt(idx + 1))) //현재, 현재+1 char 알파벳 확인
continue;
char currentChar = str.charAt(idx);
currentChar = Character.isUpperCase(currentChar) ? (char) (currentChar + ('a' - 'A')) : currentChar; //대문자 -> 소문자 변경
char nextChar = str.charAt(idx+1);
nextChar = Character.isUpperCase(nextChar) ? (char) (nextChar + ('a' - 'A')) : nextChar; //대문자 -> 소문자 변경
String tempSet = currentChar+""+nextChar; //원소 값
if(strMap.containsKey(tempSet)){ //이미 있을 경우 해시 값만 증가
strMap.put(tempSet, strMap.get(tempSet)+1);
}else { //없는 경우 해시 신규 추가 및 중복 제거된 문자열 집합에 추가
strMap.put(tempSet, 1);
strSet.add(tempSet);
}
answer++; //중복 포함 총 문자열 길이+1
}
return answer;
}
public boolean isCustomAlpha(char character){ //알파뱃 체크
return (character < 'A' || character > 'Z') && (character < 'a' || character > 'z');
}
}

